语言的边界就是世界的边界。
在本章中,我们将研究一系列用于数据存储和查询的通用数据模型。特别地,我们将比较关系模型,文档模型和少量基于图形的数据模型。我们还将查看各种查询语言并比较它们的用例。
数据模型与查询语言
关系模型与文档模型
现在最著名的数据模型可能是 SQL,它基于 Edgar Codd 在 1970 年提出的关系模型。关系数据库已经持续称霸了大约 25~30 年,现在,NoSQL 开始了最新一轮尝试,试图推翻关系模型的统治地位。
采用 NoSQL 数据库的背后有几个驱动因素,其中包括:
- 需要比关系数据库更好的可伸缩性,包括非常大的数据集或非常高的写入吞吐量
- 相比商业数据库产品,免费和开源软件更受偏爱
- 关系模型不能很好地支持一些特殊的查询操作
- 受限于关系模型的限制,渴望一种更具动态性与表现力的数据模型
不同的应用程序有不同的需求,因此,在可预见的未来,关系数据库似乎可能会继续与各种非关系数据库一起使用。
对象关系不匹配
目前大多数应用程序开发都使用面向对象的编程语言来开发,如果数据存储在关系表中,那么需要一个笨拙的转换层,处于应用程序代码中的对象和表,行,列的数据库模型之间。ORM 框架虽然可以减少这个转换层所需的样板代码的数量,但是它们不能完全隐藏这两个模型之间的差异。
例如,简历信息如果使用 SQL 数据库表示如下: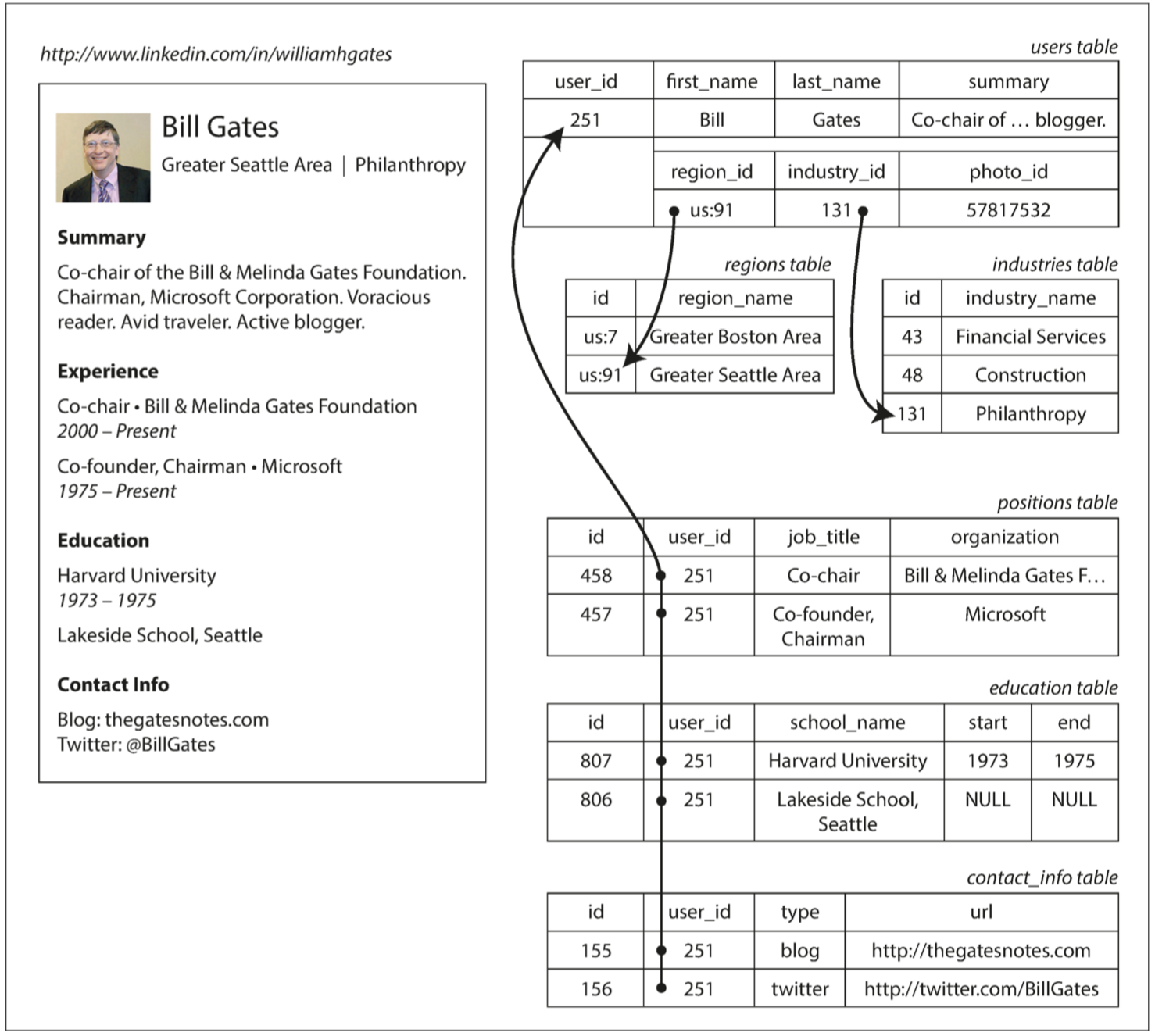
而同样的信息,使用 JSON 文档表示如下:
|
有一些开发人员认为 JSON 模型减少了应用程序代码和存储层之间的差异。不过,JSON 作为数据编码格式也存在问题,我们将在之后章节详细讨论。
关系型数据库与文档数据库的对比
将关系数据库与文档数据库进行比较时,可以考虑许多方面的差异,包括它们的容错属性和并发性。本章将只关注数据模型中的差异。
支持文档数据模型的主要论据是架构灵活性,因局部性而拥有更好的性能,以及对于某些应用程序而言更接近于应用程序使用的数据结构。
关系模型优势在于通过为连接提供更好的支持以及支持多对一和多对多的关系。
文档数据库是读时模式(schema-on-read,数据的结构是隐含的,只有在数据被读取时才被解释),相应的是写时模式(schema-on-write,传统的关系数据库方法中,模式明确,且数据库确保所有的数据都符合其模式),读时模式类似于编程语言中的动态类型检查,而写时模式类似于静态类型检查。就像静态和动态类型检查的相对优点具有很大的争议性一样,数据库中模式的强制性是一个具有争议的话题,一般来说没有正确或错误的答案。
文档和关系数据库的融合
自 2000 年代中期以来,大多数关系数据库系统都已支持 XML、JSON 文档,而在文档数据库中,一些查询语言中也支持类似关系的连接。随着时间的推移,关系数据库和文档数据库似乎变得越来越相似,数据模型得以相互补充。
数据查询语言
当引入关系模型时,关系模型包含了一种查询数据的新方法: SQL 是一种”声明式”查询语言。Web 中的 CSS 也是一种”声明式”查询语言。
声明式查询语言是迷人的,因为它通常比命令式 API 更加简洁和容易。更重要的是,它还隐藏了数据库引擎的实现细节,这使得数据库系统可以在无需对查询做任何更改的情况下进行性能提升。
图数据模型
如上所述,多对多关系是不同数据模型之间具有区别性的重要特征。如果你的应用程序大多数的关系是一对多关系(树状结构化数据),甚至大多数记录之间不存在关系,那么使用文档模型是合适的。
但是,要是多对多关系在你的数据中很常见呢?关系模型可以处理多对多关系的简单情况,但是随着数据之间的连接变得更加复杂,将数据建模为图显得更加自然。
一个图由两种对象组成:
- 顶点(vertices,也称为节点 nodes 或实体 entities)
- 边(edges,也称为关系 relationships 或弧 arcs)
典型的例子包括:
- 社交图谱: 顶点是人,边指示哪些人彼此认识
- 网络图谱: 顶点是网页,边缘表示指向其他页面的HTML链接
- 公路或铁路网络: 顶点是交叉路口,边线代表它们之间的道路或铁路线